ワテがメインで使っているパソコンはWindows 10 だ。
ちょっとした文章の作成や編集には、メモ帳も良く使うがそれ以外に Notepad++ というフリーなエディタを時々使っている。
こんな感じの画面だ。
図1. Notepad++の画面の例
多機能なので十分に使いこなせていないが、ワテが良く使うのは検索・置換機能だ。
検索結果が画面下部に一覧で表示され、なかなか使い易い。
また、検索や置換では正規表現が使えるので便利だ。
正規表現パターンを入力する部分はヒストリー機能が付いているので過去に入力した10数件くらいのパターンが候補に出て来る。
Notepad++は、こういうちょっとした気の利いた機能が使い易い。
さて、この記事では Notepad++ の正規表現を使って特定の文字列を含む行を残す方法を紹介したい。
特定の文字列を含む行を除去するのは簡単だが。
では本題に入ろう。
特定の文字列を含む行のみ残したい
データを集計している時などに、
特定の文字列を含んでいる行のみを取り出したい
という状況は良くあると思う。
例えば本日の時点での衆議院議員473名の名簿から、一部のお名前を引用すると以下の通り。
この中から金子さんを含む行のみを取り出したい。
名前 ふりがな 当選回数
遠藤 利明 えんどう としあき 7
鈴木 憲和 すずき のりかず 2
加藤 鮎子 かとう あゆこ 1
亀岡 偉民 かめおか よしたみ 3
根本 匠 ねもと たくみ 7
吉野 正芳 よしの まさよし 6
玄葉 光一郎 げんば こういちろう 8
小熊 慎司 おぐま しんじ 2
勝沼 栄明 かつぬま しげあき 2
菅家 一郎 かんけ いちろう 2
高橋 比奈子 たかはし ひなこ 2
橋本 英教 はしもと ひでのり 2
藤原 崇 ふじわら たかし 2
井上 義久 いのうえ よしひさ 8
真山 祐一 まやま ゆういち 1
升田 世喜男 ますた せきお 1
村岡 敏英 むらおか としひで 2
金子 恵美 かねこ えみ 1
郡 和子 こおり かずこ 4
近藤 洋介 こんどう ようすけ 5
寺田 学 てらた まなぶ 4
高橋 千鶴子 たかはし ちづこ 5
石崎 徹 いしざき とおる 2
細田 健一 ほそだ けんいち 2
金子 めぐみ かねこ めぐみ 2
長島 忠美 ながしま ただよし 4
高鳥 修一 たかとり しゅういち 3
表1. 衆議院議員473名の名簿の一部(このリストには金子さんは二名いる)
名簿をNotepad++ で開いた状態
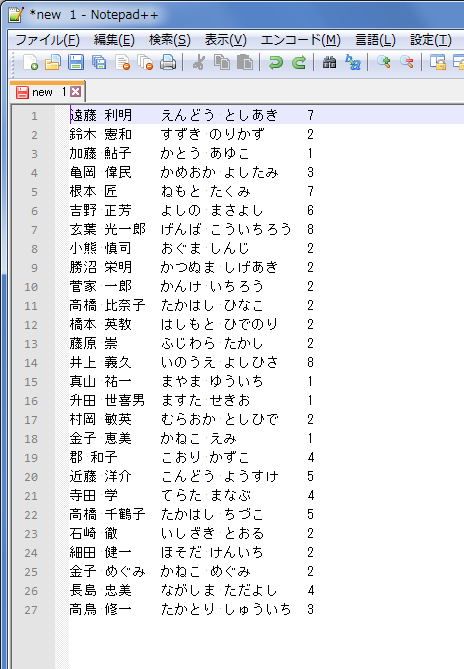
図2. 名簿をNotepad++で開いた画面
「金子」さん以外を除去する
置換ダイアログを表示する
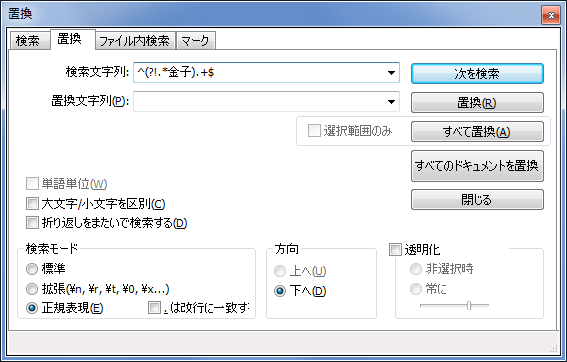
図3. Notepad++の置換ダイアログ画面
検索文字列1 ^(?!.*金子).+$
置換文字列1 空文字列
と入力して[すべて置換]をクリックすると下図のようになる。
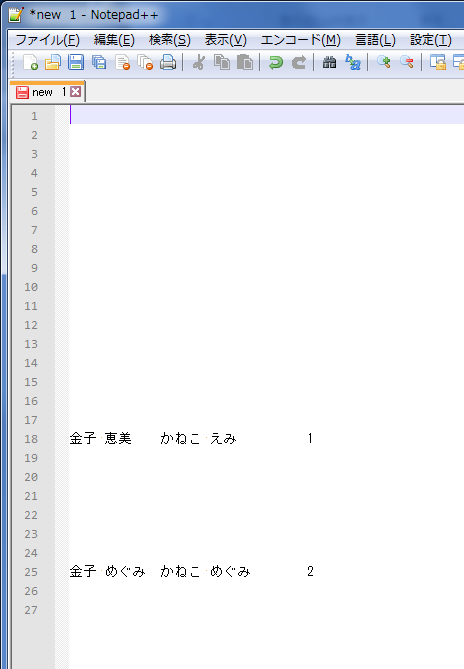
図4. 金子さん以外を除去した(実行結果)
金子さん以外が空行に置き換わった。
空行を除去したい
同じく置換ダイアログで以下のように入力する。
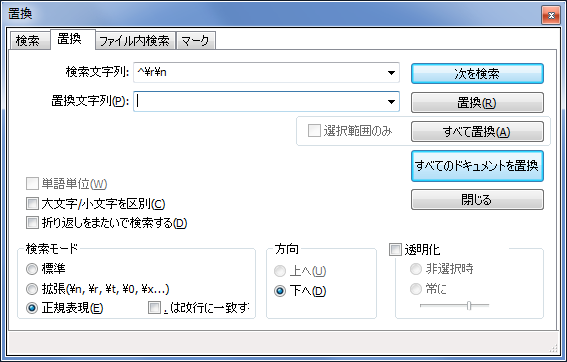
図5. 空行を除去する設定(実行前)
検索文字列2 ^\r\n
置換文字列2 空文字列
と入力して[すべて置換]をクリックすると下図のようになる。
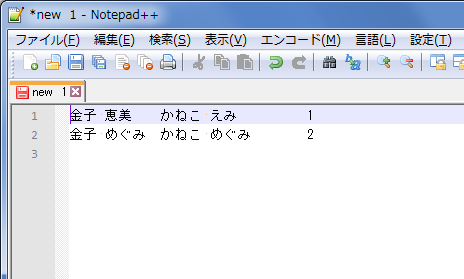
図6. 空行を除去した(実行結果)
目的の金子さんのみ取り出すことが出来た。
もし一気にやりたい場合は、
検索文字列3 ^(?!.*金子).+\r\n
置換文字列3 空文字列
で行ける。
応用編
上の例では「金子」さん以外を除去した。
では、もし「金子」さんと「橋本」さん以外を除去したいなら
検索文字列4 ^(?!.*(金子|橋本)).+$
置換文字列4 空文字列
で行ける。
同時に空行も除去したいなら、
検索文字列5 ^(?!.*(金子|橋本)).+\r\n
置換文字列5 空文字列
で行ける。
その実行結果を下図に示す(Windows10で実行したのでウインドウの見た目が変わった)。
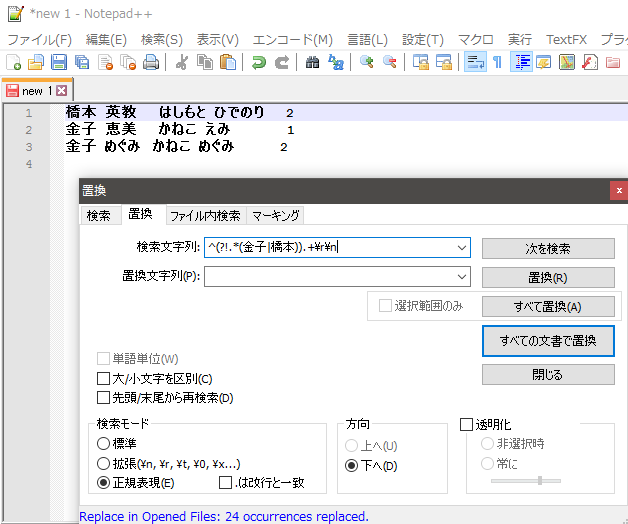
図7. 金子さんと橋本さん以外を除去する設定と実行結果
この正規表現の解説(自分用のメモ)
良く忘れるので、備忘録としてメモしておくと、
検索文字列1 ^(?!.*金子).+$
この正規表現を分解すると以下のようになる。なお金子さんの敬称は略してある。
| ^ | 先頭から読んで行って |
| (?! | 否定先読み |
| .* | 0文字以上の文字が有って |
| 金子 | 金子が来た。否定先読みなので、要するに 先頭^から何か文字列(.*)があり金子でない文字列が有ったら=>つまり金子を含まない文字列 |
| ) | 否定先読みを閉じる |
| .+$ | その文字列(=金子を含まない文字列)から末尾までは任意の文字列 |
表2. 金子さん以外を除去する正規表現の説明(ワテ流)
MSDNの説明
| 正規表現 | 説明 |
| ^ | 行の先頭 |
| (pattern) | pattern と一致した文字列を記憶する部分式(今は↓の否定先読みの部分式) |
| (?!pattern ) |
否定先読み検索を実行する部分式 pattern に一致しない文字列が始まる位置にある検索文字列と一致する。 |
| . | 任意文字列 |
| * | 0回以上の繰り返し |
| + | 1回以上の繰り返し |
| $ | 行末 |
表3. 否定先読みなどの説明(MSDNから引用)
ワテは、この表の否定先読みの部分の説明文は何度読んでも良く分からないので、実際に試してみるのが一番だ。
否定先読みの理解
ワテの場合、「否定先読み」の動作が覚えられない。
良く分からないまま使っている感じ。
正規表現と言うのは、何らかのパターンにマッチする文字列を見付けるのが目的だが、
否定先読み
肯定後読み
否定後読み
などは、文字列を見付けるのではなくて、文字と文字の間の位置を見付けると考えると良いのかな。
同じく行頭^や行末$も文字ではなくて、位置に一致させる訳だからそれと同じ考え方。
例えば、
入力文字列 abcdef
としよう。
肯定先読み (?=def)
肯定先読み (?=def) は、その直後にパターンdefがある位置(cとdの間)に一致する。
abc■def
この ■ の位置にマッチするのだ。
否定先読み (?!def)
否定先読み (?!def) は、その直後にパターンdefが無い位置に一致する。
■a■b■cd■e■f■
この例だと、六ケ所の■位置にマッチする。
「金子」さんを含まない行を取り出すパターンを復習する
冒頭の金子さんを含まない否定先読みの場合は以下のパターンを使った。
検索文字列1 ^(?!.*金子).+$ 置換文字列1 空文字列
この場合、
(?!.*金子)
は、「・・・金子」を含まない全ての位置にマッチすると言う意味になる。
従って、入力文字列が以下の場合には、
私は忌野清志郎です (全ての位置にマッチする)
となる。
そこに、^を付けると、金子を含まない位置のうち、先頭位置にマッチして、そこから末尾まで(.+$)
^(?!.*金子).+$
と言う事か。
それを空文字列に置換すると、金子を含まない行は消えるのだ。
と言う動作になるのかな。
先読みと後読み(戻り読み)の違い
先読み マッチ位置の直後の条件を指定する
後読み(戻り読み) マッチ位置の直前の条件を指定する
と言う事か。
アマゾンで正規表現の本を見る


ワテは読んでいないが↑の本はアマゾンレビューでも評価が高い。


達人の技を盗むと良い。
あと、この2冊は正規表現のバイブルみたいなもんか。有名な本だ。




共に500ページ前後もの分量なので、ワテの場合、昔購入したが途中で挫折した。


コメント